Introduction
I have been learning a lot of math lately. I now know more math than I ever fathomed I would, more than I knew there was out there to learn. This is great, and has given me a (much improved) altered view of the world. I now see and approach everything through mathematical lenses. Even the most mundane or routine day-to-day tasks can benefit from this outlook. For example: Decorating the Christmas tree.
The problem
It seems like just about everybody is concerned with ensuring the ornaments on the Christmas tree are placed evenly, and there is no bunching or grouping of ornaments on one side of the tree versus the other. This is usually achieved by eyeballing it; a totally subjective experience. Well, this concern came up again this year as it often does, except this time, I had my mathematical lenses...
Lets say you want to achieve near-perfect spacing of the ornaments on your Christmas tree, and all you have is a ruler, or maybe a carpenters square (apparently Sheldon does this on The Big Bang Theory, as my friend explained to me while I was writing this).
You can figure out the number of ornaments you have, since you can count them, so how do you know how far apart to space each ornament?
The strategy
Thinking about it, it seems the simplest way would be to divide the number of ornaments you have over the area of the ornament-hanging real estate, and we would get a result in terms of 1 ornament per X feet^2. I think we can work with that.
Surface area of the ornament-space of a standard tree
The formula for calculating the surface areas is well know for a wide variety of shapes. Given a shape, we can just google for the formula. Take a gander at your Christmas tree, what shape does it remind you of? Well, its conical. We can generalize a Christmas tree to the shape of a cone:

Now when I first did this, the result I got just didn't seem right, I was getting a result of ~91.5 square feet. There was no way my tree was exposing 91 square feet of ornament space! Well, the surface area of a cone includes the base, of course, and not too many people hang Christmas ornaments underneath of the tree. Whoops!
So after some googling, I found out that the surface area of the slanted part of the cone is called the Lateral Surface Area of a cone.
The formula

So all that is required is for you measure the radius of your Christmas tree, the height from the base, plug those numbers into the above formula, and that returns the surface area in square units. The units are whatever units you put into the formula, typically inches.
Note: The radius (r) is measured from the trunk out to the end of the branches at the base. The height (h) is measured from the base to the top. Do not measure from the floor to the tip, as this will include the length of the trunk, and since the surface area per unit of height is greatest at the bottom, this will throw your surface area calculation off by a lot.
Then, dividing the number of ornaments you have by the surface area gives you the number or ornaments per square unit. You can then at this point, cut out a square piece of paper to match the area that one ornament should occupy. Do this four times to make four squares. If you have thicker paper or card stock, use that. Tape the four squares together, two on top, two on bottom, offset by half a square, like seen here:
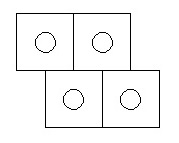
This will be your template. This gives you a frame of reference, so you can align ornaments in reference to ones already hung. You can even draw and cut out circles in the center to obviate any need for guesswork or eye-balling their placement.