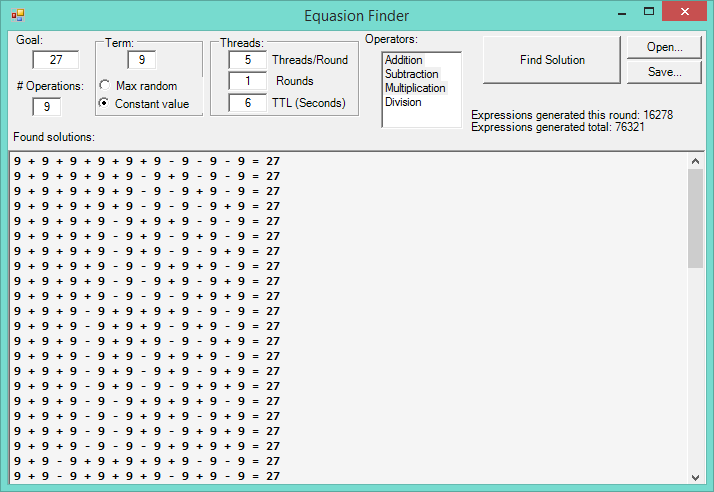
Threaded Equation Finder
Find arithmetic equations that equates to a given 'target' value, number of terms, and operators.
Introduction
You should all be familiar with how a typical computer works; you give it some variables, describe some quantities of some resources you have, choose an algorithm, let it process, and it returns to you a result or outcome. Now imagine a computer if you could work with a computer that worked the other way around. I believe it was Douglas Adams that described the notion of an all-together different type of computer; That is, you tell the computer what you want the outcome to be, and it goes off figuring out how to get there and what you need to do it.
Z3, the Theorem Prover, and the constraint satisfaction problem (CSP) solver (and probably others) in
Microsoft's Solver Foundation do almost exactly that.
There is also the idea of
Backcasting, which is a similar, but different idea.
My program isn't as fancy as all that, but it does find equations that equates to a given 'target' value, albeit at random. You define constraints other than just the target value, such as what operators are allowed in the equation, the quantity of terms there, and the range or set of allowed terms.
For example, how many different ways can 9 nines equal 27, using only addition, subtraction, and multiplication, if evaluated left-to-right (ignore the order of operations)? Turns out
there are only 67 ways.
(above) Application Screen Shot
How it works
The actual approach for finding equations that equate to an arbitrary target or 'goal' value is rather primitive. By way of Brute Force, several threads are launched asynchronously to generate thousands of random equations, evaluate them and keep the results that have not been found yet.
This is something I wrote approx. 2 years ago. I dug it up and decided to publish it, because I thought it was interesting. As this was an 'experiment', I created different ways of storing and evaluating the expressions, and have made those different 'strategies' conform to a common interface so I could easily swap them out to compare the different strategies. I have refactored the code so that each class that implements IEquation is in its own project and creates its own assembly.
There are two fully-working strategies for representing equations: one that represented the equation as a list of 2-tuples (Term,Operator), did not perform order of operations, and was rather obtuse. The other strategy was to store the equation as a string and evaluate it using MSScriptControl.ScriptControl to Eval the string as a line of VBScript. This was unsurprisingly slower but allowed for much more robust equation evaluation. Order of operations is respected with the ScriptControl strategy, and opens the way to using using parenthesis.
The other idea for a strategy which I have not implemented but would like to, would be a left-recursive Linq.Expression builder. Also, maybe I could somehow use Microsoft Solver Foundation for a wiser equation generation strategy than at random.
Limitations
Today, however, there are better architectures. A concurrent system like this would benefit greatly from the Actor model. If you wanted to write complex queries against the stream of equations being generated or selected or solved, maybe reactive extensions would be a slam dunk.
Although this project certainly is no Z3, it does provide an example of an interface... perhaps even a good one.
Running on Raspberry Pi 2
Microsoft's
Managed Extensibility Framework (MEF) might be a good thing here, but I also wrote a console client that is designed to be ran with Mono on the Raspberry Pi 2. MEF is a proprietary Microsoft .NET technology that is not supported in Mono. The extra meta data in the assembly shouldn't be a problem, but having a dependency on the MEF assembly will be. Probing of the runtime environment and dynamically loading of assemblies is required here, which I have not had time to do, so at this time, there is no MEF.
The reason the mono client is a console application is because mono and winforms on the Raspberry Pi 2 fails for some people. The problem has something to do with a hardware floating point vs a software float, and it happens to manifest itself when using a TextBox control. The only thing that I haven't tried, and that should presumably fix it, is to re-build mono from the latest source.