Tuesday, July 5, 2016
True hardware random number generator with the Raspberry PI
So, I have been getting into cryptology lately, (For my most recent projects that I may or may not have blogged about at this point, see Bloom Filter and RC4Ever on GitHub).
The other day, I had a need for a TRUE random number generator, so I was searching the web for a hardware random number generator, when I found some very pleasant information: I already own one!
As it turns out, the Raspberry Pi (A/A+/B/B+/and 2) includes a hardware based random number generator, and according to many sources, its a very good source of truly random bytes. Yay!
To get this working on your own Pi, its a breeze:
1) Install the RasPi's random number generator tools: sudo apt-get install rng-tools.
2) Add to the boot process file (/etc/modules.conf) the command to run the hwrng module: bcm2708-rng.
3) Reboot the Pi.
Now, /dev/hwrng is available for reading. Its treated like a device, and you can use the dd command to copy bytes from the device stream to a file (like examples you might have seen doing the same from /dev/random).
NOTE: /dev/hwrng is accessible by the user root only.
But we can change that! The following command gives the user level read access: sudo chmod a+r /dev/hwrng
NOTE: This setting gets reset upon every reboot.
Again, we can change that: Add the following line to /etc/rc.local file, just above the exit 0 line:
chmod a+r /dev/hwrng
And its just that easy!
Now, say if you want to generate 1 megabyte worth of random bytes to a file in /tmp, simply enter the following command into a terminal:
dd if=/dev/hwrng of=hwrng-test-data.bin bs=1024 count=1024
The bs argument specifies the size to buffer before writing to disk. You probably want to leave that at or around 1024. Its the count argument that specifies the size, or amount, of data you want to copy from /dev/hwrng, in Kilobytes. So 1024 == 1 MB, where as 1 == 1KB.
Now, its time for Step 4) Create a C# helper library to simplify the retrieval of random bytes from /dev/hwrng.
So there is two ways to approach this. One is to make a C++ library that makes native calls and then write a .NET interop library to wrap that Or, if you are like me, a little lazy, and find that ever since transitioning to C# you find it difficult to write anything in C or C++ that compiles, you may opt to just issue the above commands to the shell and just read in the resulting file from the tmp directory.
As hackey as this second option might seem, it works remarkably well and I have written a GitHub project doing just that. It consists of a library to return random bytes, and a console executable exercising said library to get random bytes. Links below!
- The PiRngWrapper GitHub Project
- The PiRngWrapperLibrary.cs wrapper code file
Wednesday, June 29, 2016
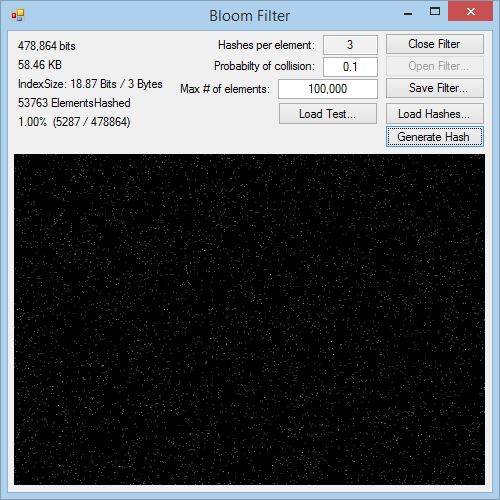
Bloom Filter - A novel, space efficient data structure like a hash-table for billions of values.
Introduction
A bloom filter is a truly novel data structure. Similar to a hash table, it can tell you if you've hashed a particular value previously. You can add many, many more values to a bloom filter than you can to a hash table, does not degrade performance as the number of values in the set grows large, and requires only a fraction of the space of a hash table to store it!
This is not just an academic exercise, or something that only works in theory or in special cases. Indeed, companies like google use bloom filters to quickly determine if it has never seen that value before, thus avoiding a more costly lookup against a database every time the bloomfilter returns false.
Probabilistic
First off, its important to understand that a bloom filter is NOT a hash table, it operates in an entirely different way. A bloom-filter is what is known as a probabilistic data structure. What this means is, that it can tell you to within a certain probability, if an element exists in a set. In other words, false positive matches ARE possible, but false negative matches ARE NOT possible. For example, if you check a bloom filter for the existence of a value, and it returns false, you can know with 100% certainty that the bloom filter does not contain that value value before. However, if you test a value against the filter and it returns true, there is a small probability that it has in fact not seen that value before, but is returning a false positive. How big of a probability? Here's the beauty: It can be as small as you want it to be. It depends on a few factors, including the size of the filter, how full it is, and how many bits you use to store each value in the filter.
In a HashTable class, each item is stored as a key value pair, so the size of your object plus a 32 bit integer. Contrast that to a bloom filter, which stores only about 3-7 bits per value hashed. Also, my implementation applies compression when saving the filter to disk, providing even more space savings. A bloom filter with 160,000 values hashed and a 1% collision probability results in a filter that is 235KB uncompressed, and a whopping 54KB when compressed! Remember the filter is an array of bits. The entropy of the array is going to be at its greatest, and thus the compression ratio lowest, when exactly 1/2 of the bits are flipped, or the filter is half-way 'full'. This has the unusual property of getting smaller as you add more hashes to the filter. Actually, this is misleading--the actual filter itself never changes size, its only the compressed version that varies in size.
To handle the compression I just used the System.IO.Compression.DeflateStream class. An important note about working with this class: build an array of bytes and send your entire file in one go. In this way it will compress the whole file as one chunk. If you sent data to this stream piecemeal, it will compress each piece separately and you will get a poor compression ratio.
How it works
So how does this all work? The filter part of a bloom filter is just a large array of bits. You also require several different hash functions that each return a unique result for the same input value. When you add a value to the filter, the value is sent to about 3-7 different hash functions. Each hash function will return a value that is between 0 and the number of bits in the filter. Each value is used as an index to access and element on the array of bits that is your filter. When hashing a value, you just set the bit at each index location in the array to 1. Then testing for the presence of a value in the filter, you pass the value to the hash functions the same way as above, then visit each index, checking to see if any of them are 0. If even one bit at one of those index positions are zero, it means the filter has never seen that value before, because it would have set all those bits to 1. If all the bits at the index locations are 1, then it is likely that the filter has seen that value before. However,there is a chance that it is a false positive, because it could be that that value's different hashes all mapped to bits from other values. As the filter becomes more full, more bits are set to 1, and so the odds of a false positive go up. To build your filter by supplying the estimated number of values you think you are likely to store in the filter, and don't go above a certain ratio of 1 bits to 0 bits. If you were to let your filter hash so many values that every bit got set to 1, then the probability of receiving a false positive for a random value becomes 100%.
Solving the many hash problem
As I mentioned before, this requires several different hash functions that each return a unique result for the same input value. Although I said 3-7 hash functions, you might require 14 or more, when working with filters that can handle large number of hashes or a low false positive likelihood or both.Instead of writing a bunch of separate hash algorithms, I implemented a stream cipher where in I just scramble the cipher table by a number of rounds that is unique to that input. Then, I can return as many indices as the filter is configured for. This sets up the table once per value. It needs to reset the table or else the indices that we mark will depend on every value that came before it, and in that particular order. Currently the bottle-neck is how many times it has the scramble the table for each value. If you need to hash really long values, you'll want to lower the number of rounds it scrambles the table.
Variations
In this implementation, the bloom-filter size is set once you create it, meaning that it cannot grow bigger if it gets too full, nor can you resize this bloom filter to become smaller if you sized it too big. Because multiple values could rely on the same bit, this implementation does not support removal of items, because to do so would cause several values to begin reporting false negatives.
In order to make a bloom filter that supports deletion, use a number like a byte instead of bits in your filter, and each time you visit an index in the filter while adding values, increment the number you find there. Then, to delete a value, visit each index as you did before, but decrement the number there. This way, if two values map to the same index, that information is tracked by incrementing the value. This is what is known as a Counting Bloom Filter.
There are other variants of bloom filters out there, including bloom filters that can grow in size if it gets too full, but such a thing is beyond the scope of my needs. In essence, when the filter gets too full, you create another separate filter, and add new values by first checking the first filter to see if it exists, and if not, adding the value to the second filter. Checking for the presence of a value requires checking both (and other) filters. For information on scalable bloom filters, please see this whitepaper.
The code
My C# Bloom Filter project on GitHub
Or download zip here.
Sunday, June 12, 2016
The biggest problem with Mathematics today
I start this time with a little disclaimer: This is, after all, a blog, and most blogs still fit the original definition, which is a public forum used for a person to state or explain their beliefs and/or feelings. So it is without further ado, that I proceed, unabashed:
The biggest problem with Mathematics today, particularly around people approaching, or new to the field, is the conventions of naming things.
Historically, and seemingly by convention, mathematical concepts are named after the first person to define or make serious contributions to that field. This is what is known as an eponym.
This is terrible practice, even tear-able! I am bitter about the amount of time I waste trying to find the 'name' of the mathmatical concept I wish to express or research, or when I have to derail my research to go define a term or concept I don't recognize, only to find out that I am already know what it was.
If people would just name stuff after what it actually fucking does, instead of some person's last name, we would all be a lot better off (except for maybe the aforementioned person).
In software development, we have this concept known as refactoring. This term includes fundamental re-structuring of the code, but also can be as simple as a bunch of renaming of everything to fit a more consistent, or holistic, view or concept. A similar thing needs to happen to the field of mathematics, and sooner rather than later!
No more eponyms in Mathematics!
The biggest problem with Mathematics today, particularly around people approaching, or new to the field, is the conventions of naming things.
Historically, and seemingly by convention, mathematical concepts are named after the first person to define or make serious contributions to that field. This is what is known as an eponym.
This is terrible practice, even tear-able! I am bitter about the amount of time I waste trying to find the 'name' of the mathmatical concept I wish to express or research, or when I have to derail my research to go define a term or concept I don't recognize, only to find out that I am already know what it was.
If people would just name stuff after what it actually fucking does, instead of some person's last name, we would all be a lot better off (except for maybe the aforementioned person).
In software development, we have this concept known as refactoring. This term includes fundamental re-structuring of the code, but also can be as simple as a bunch of renaming of everything to fit a more consistent, or holistic, view or concept. A similar thing needs to happen to the field of mathematics, and sooner rather than later!
No more eponyms in Mathematics!
Friday, January 22, 2016
Trick: How to mentally convert and calculate rate of pay
I have been real busy lately, so I will share only a short tip this week. However, I have some cool new projects/concepts I have been working on, such as a term rewriting system, so keep checking back.
I have been interviewing for a new job, its time to move up. Often I am quoted an annual salary, and I want to see how that compares with hourly wage. I do this calculation in my head, on the spot, and so can you. This technique leverages Estimation/Approximation.
Since 40hrs/week times 52wks/year = 40 * 52 = 2080 full-time work hours in a year.
We can use approximation by multiplying or dividing by 2000. Since we know that 2 * 1000 = 2000, multiplying/diving by 2000 is trivial. Remember, to multiply or divide by any power of ten, now matter how great, just count the zeros and just shift the decimal place once to the right, or towards a smaller quantity, that number of times. e.g. 43.50 * 1000 = 43,500
'So how large is the error from estimating?', One might ponder... Well ponder no more! Hark:
Estimation Error - From hourly to yearly--
$12/HR @ 40HR/WK
$24,000/YR - Estimated
$24,960/YR - Actual
-------
-$960 - Difference
$25/HR @ 40HR/WK
$50,000/YR - Estimated
$52,000/YR - Actual
-------
$2,000/YR - Difference
$50/HR @ 40HR/WK
$100,000/YR - Estimated
$104,000/YR - Actual
--------
$4,000 - Difference
Estimation Error - From yearly to hourly--
$25K/YR @ 40HR/WK
$12.50/HR - Estimated
$12.02/HR - Actual
------
-$0.48/HR - Difference
$50K/YR @ 40HR/WK
$25.00/HR - Estimated
$24.04/HR - Actual
------
-$0.96/HR
$100K/YR @ 40HR/WK
$50.00/HR - Estimated
$48.07/HR - Actual
------
-$1.92/HR
Thursday, December 24, 2015
Infix Notation Parser via Shunting-Yard Algorithm
Infix notation is the typical notation for writing equations in algebra.
An example would be: 7 - (2 * 5)
Parsing such an equation is not a trivial task, but I wanted one for my EquationFinder project, as I wanted to respect order of operations.
Strategies include substitution/replacement algorithms, recursion to parse into a tree and then tree traversal, or converting the infix notation to reverse polish notation (RPN), also known as post-fix notation, then using a stack based postfix notation evaluator. I choose the latter, as such algorithms are well defined in many places on the web.
My code consists of 3 classes, all static:
(Links go to the .cs file on GitHub)
- InfixNotation - this simply holds a few public variables and calls the public methods on the below two classes.
- ShuntingYardAlgorithm - this converts an equation in infix notation into postfix notation (aka RPN).
- PostfixNotation - this evaluates the equation in postfix notation and returns a numerical result value.
In order to implement the shunting-yard algorithm and the postfix evaluator, I simply wrote the steps to the algorithms as written on Wikipedia:
(Links go to the Wikipedia article)
Link to the Shunting-Yard Algorithm to convert Infix notation to Postfix notation.
Link to the Postfix Notation Evaluation Algorithm.
The code for this is pretty extensive, but I will prettify it and present it below. Alternatively, you can view and download the code from the MathNotationConverter project on my GitHub.
InfixNotationParser:
public static class InfixNotation
{
public static string Numbers = "0123456789";
public static string Operators = "+-*/^";
public static bool IsNumeric(string text)
{
return string.IsNullOrWhiteSpace(text) ? false : text.All(c => Numbers.Contains(c));
}
public static int Evaluate(string infixNotationString)
{
string postFixNotationString = ShuntingYardConverter.Convert(infixNotationString);
int result = PostfixNotation.Evaluate(postFixNotationString);
return result;
}
}
ShuntingYardConverter
(converts an equation from infix notation into postfix notation):
public static class ShuntingYardAlgorithm
{
private static string AllowedCharacters = InfixNotation.Numbers + InfixNotation.Operators + "()";
private enum Associativity
{
Left, Right
}
private static Dictionary<char, int> PrecedenceDictionary = new Dictionary<char, int>()
{
{'(', 0}, {')', 0},
{'+', 1}, {'-', 1},
{'*', 2}, {'/', 2},
{'^', 3}
};
private static Dictionary<char, Associativity> AssociativityDictionary = new Dictionary<char, Associativity>()
{
{'+', Associativity.Left},
{'-', Associativity.Left},
{'*', Associativity.Left},
{'/', Associativity.Left},
{'^', Associativity.Right}
};
private static void AddToOutput(List<char> output, params char[] chars)
{
if (chars != null && chars.Length > 0)
{
foreach (char c in chars)
{
output.Add(c);
}
output.Add(' ');
}
}
public static string Convert(string infixNotationString)
{
if (string.IsNullOrWhiteSpace(infixNotationString))
{
throw new ArgumentException("Argument infixNotationString must not be null, empty or whitespace.", "infixNotationString");
}
List<char> output = new List<char>();
Stack<char> operatorStack = new Stack<char>();
string sanitizedString = new string(infixNotationString.Where(c => AllowedCharacters.Contains(c)).ToArray());
string number = string.Empty;
List<string> enumerableInfixTokens = new List<string>();
foreach (char c in sanitizedString)
{
if (InfixNotation.Operators.Contains(c) || "()".Contains(c))
{
if (number.Length > 0)
{
enumerableInfixTokens.Add(number);
number = string.Empty;
}
enumerableInfixTokens.Add(c.ToString());
}
else if (InfixNotation.Numbers.Contains(c))
{
number += c.ToString();
}
else
{
throw new Exception(string.Format("Unexpected character '{0}'.", c));
}
}
if (number.Length > 0)
{
enumerableInfixTokens.Add(number);
number = string.Empty;
}
foreach (string token in enumerableInfixTokens)
{
if (InfixNotation.IsNumeric(token))
{
AddToOutput(output, token.ToArray());
}
else if (token.Length == 1)
{
char c = token[0];
if (InfixNotation.Numbers.Contains(c)) // Numbers (operands)
{
AddToOutput(output, c);
}
else if (InfixNotation.Operators.Contains(c)) // Operators
if (operatorStack.Count > 0)
{
char o = operatorStack.Peek();
if ((AssociativityDictionary[c] == Associativity.Left &&
PrecedenceDictionary[c] <= PrecedenceDictionary[o])
||
(AssociativityDictionary[c] == Associativity.Right &&
PrecedenceDictionary[c] < PrecedenceDictionary[o]))
{
AddToOutput(output, operatorStack.Pop());
}
}
operatorStack.Push(c);
}
else if (c == '(') // open brace
{
operatorStack.Push(c);
}
else if (c == ')') // close brace
{
bool leftParenthesisFound = false;
while (operatorStack.Count > 0 )
{
char o = operatorStack.Peek();
if (o != '(')
{
AddToOutput(output, operatorStack.Pop());
}
else
{
operatorStack.Pop();
leftParenthesisFound = true;
break;
}
}
if (!leftParenthesisFound)
{
throw new FormatException("The algebraic string contains mismatched parentheses (missing a left parenthesis).");
}
}
else // wtf?
{
throw new Exception(string.Format("Unrecognized character '{0}'.", c));
}
}
else
{
throw new Exception(string.Format("String '{0}' is not numeric and has a length greater than 1.", token));
}
} // end foreach
while (operatorStack.Count > 0)
{
char o = operatorStack.Pop();
if (o == '(')
{
throw new FormatException("The algebraic string contains mismatched parentheses (extra left parenthesis).");
}
else if (o == ')')
{
throw new FormatException("The algebraic string contains mismatched parentheses (extra right parenthesis).");
}
else
{
AddToOutput(output, o);
}
}
return new string(output.ToArray());
}
}
PostfixNotation
(evaluates the postfix notation and returns a numerical result):
public static class PostfixNotation
{
private static string AllowedCharacters = InfixNotation.Numbers + InfixNotation.Operators + " ";
public static int Evaluate(string postfixNotationString)
{
if (string.IsNullOrWhiteSpace(postfixNotationString))
{
throw new ArgumentException("Argument postfixNotationString must not be null, empty or whitespace.", "postfixNotationString");
}
Stack<string> stack = new Stack<string>();
string sanitizedString = new string(postfixNotationString.Where(c => AllowedCharacters.Contains(c)).ToArray());
List<string> enumerablePostfixTokens = sanitizedString.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries).ToList();
foreach (string token in enumerablePostfixTokens)
{
if (token.Length > 0)
{
if (token.Length > 1)
{
if (InfixNotation.IsNumeric(token))
{
stack.Push(token);
}
else
{
throw new Exception("Operators and operands must be separated by a space.");
}
}
else
{
char tokenChar = token[0];
if (InfixNotation.Numbers.Contains(tokenChar))
{
stack.Push(tokenChar.ToString());
}
else if (InfixNotation.Operators.Contains(tokenChar))
{
if (stack.Count < 2)
{
throw new FormatException("The algebraic string has not sufficient values in the expression for the number of operators.");
}
string r = stack.Pop();
string l = stack.Pop();
int rhs = int.MinValue;
int lhs = int.MinValue;
bool parseSuccess = int.TryParse(r, out rhs);
parseSuccess &= int.TryParse(l, out lhs);
parseSuccess &= (rhs != int.MinValue && lhs != int.MinValue);
if (!parseSuccess)
{
throw new Exception("Unable to parse valueStack characters to Int32.");
}
int value = int.MinValue;
if (tokenChar == '+')
{
value = lhs + rhs;
}
else if (tokenChar == '-')
{
value = lhs - rhs;
}
else if (tokenChar == '*')
{
value = lhs * rhs;
}
else if (tokenChar == '/')
{
value = lhs / rhs;
}
else if (tokenChar == '^')
{
value = (int)Math.Pow(lhs, rhs);
}
if (value != int.MinValue)
{
stack.Push(value.ToString());
}
else
{
throw new Exception("Value never got set.");
}
}
else
{
throw new Exception(string.Format("Unrecognized character '{0}'.", tokenChar));
}
}
}
else
{
throw new Exception("Token length is less than one.");
}
}
if (stack.Count == 1)
{
int result = 0;
if (!int.TryParse(stack.Pop(), out result))
{
throw new Exception("Last value on stack could not be parsed into an integer.");
}
else
{
return result;
}
}
else
{
throw new Exception("The input has too many values for the number of operators.");
}
} // method
} // class
Another alternative technique is to using the Shunting-Yard Algorithm to turn infix notation into an abstract syntax tree (Linq.Expressions anyone?). I will likely post this technique later.
Other blog posts by me that are related to this article are the Threaded Equation Finder, a Mixed Radix System Calulator and Drawing Text Along a Bezier Spline.
Subscribe to:
Posts (Atom)